19 min to read
1.Incident Handling Overview
eCIR - Part 1 Summary

Table of Contents
- Incident Handling Defintion & Scope
- Security Incidents & Events
- Incident Handling Process (IR Life Cycle)
- Preparation
- Detection & Analysis (Identification)
- Containment, Eradication & Recovery
- Post-Incident Activity (Lesson Learned)
- Appendix
- Windows Cheat Sheet
- Linux Cheat Sheet
- References
Incident Handling Definition & Scope
- It is the action or plan of dealing with intrusions, cyber theft, DOS, and other computer or network security-related events.
- This plan should include hooks to the general disaster recovery and business continuity plans that deal with fire, floods, and other disastrous events.
- The scope of IH is greater than just intrusions; it covers insider crime and intentional/unintentional events that cause a loss of availability.
- The IH plans & policies must comply with the applicable laws of the country.
Security Incidents & Events
Incident
- Refers to an adverse event in an information system or network, implies harm or the attempt to harm.
- “Only events with negative consequences” (According to this NIST guide)
Event
Any observable occurrence in a system or network, it must be recorded & logged.
Examples:
- System crashes
- Packet flooding within a network
- Boot Sequence of the system
- Unauthorized use of another user’s account
- Unauthorized use of system privileges
- Unauthorized access to sensitive data
- Execution of malicious code or destructive malware
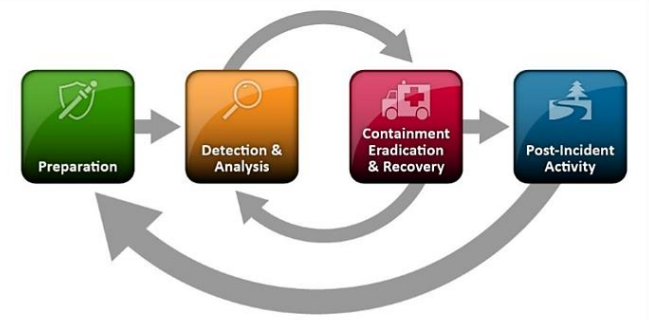
Incident Handling Process (IR Life Cycle)
The incident handling process consists of four (4) phases (known as “Incident Response Life Cycle”) :
- Preparation
- Detection & Analysis (Identification)
- Containment, Eradication & Recovery
- Post-Incident Activity (Lesson Learned)
1. Preparation
(getting the team ready to handle any incident)
- Employees
- A Skilled Response Team
- IT Security Training
- Security Awareness/Social Engineering Exercises, etc.
-Documentation
- Well-defined policies
- Ensure you have the right to monitor and collect the required amount of evidence.
- Advice from the legal department is required.
- Well-defined response procedures
Based on last 2 points, you will decide how you will handle “major” incidents (Agreement of the upper-management is required) ;
- Should the respective cybercrime unit be notified?
- Contain immediately or closely monitor the intruder?
- Breach/incident communication plan(s)
- Maintaining a chain of custody of actions
-Defensive Measures
- A/V, (H)IDS, DLP, EDR, Security Patches
- SIEM, UTM, Threat Intelligence
- NSM, Central Logging, Honeypots, etc.
-Key Points:
- Multi-disciplinary team: Incident Handlers | Forensic Analysts | Malware Analysts | Support from NOC, Legal, PR Depts.
- Determine scheduling / minimum time to respond.
- Incident handlers should have unrestricted and on-demand access to systems.
- Establish a SPOC. (Single Point Of Contact)
- Establish effective reporting capabilities.
- Incident Handling Starter Kit : Data Acquisition software | Read-only diagnostic software | Bootable Linux environment | HDs, Ethernet TAP, Cables, Laptop
2. Detection & Analysis (Identification)
(includes everything related to detecting an incident)
-Means of detection
- Sensors (FW, IDS, Agents, Logs, etc.)
- Personnel (Need to be trained)
-Information and knowledge sharing
-Context-aware threat intelligence
-Segmentation of the architecture
-Good understanding of / visibility in your network
-Key Points:
- Assign a Primary Incident Handler:
- Usually serves under the incident handling team’s manager
- In charge when handling incidents of specific class and severity
- Establish trust and effective information sharing.
- Safeguard information sharing:
- In case of a network under your supervision being compromised, alternative communications should be established.
- Good options are cloud-based services featuring end-to-end encryption, emails powered by PGP, S/MIME, etc.
- Avoid solutions that can be intercepted by an attacker in a privileged network position (Man in The Middle)
- Establish baselines, extend visibility, and know your limits:
- Catching all intrusions or intrusion attempts is unlikely, Advanced adversaries always exist.
- Admins, SOC/CSIRT members are expected to be able to spot deviations from normal network or host state/behavior (this requires baselining).
- Visibility should be extended (and fine-tuned) as much as possible, so that data exist for later analysis.
-
An effective and actionable way to logically categorize your network is by considering the following levels:
Network perimeter Host perimeter Host-level Application-level - Establish levels of detection by logically categorizing your network ;
- Network perimeter
- Detection occurs on the network
- Firewalls, NIDS, IPS, DMZ systems, etc. can assist such detection activities.
-
Wireshark detection example:
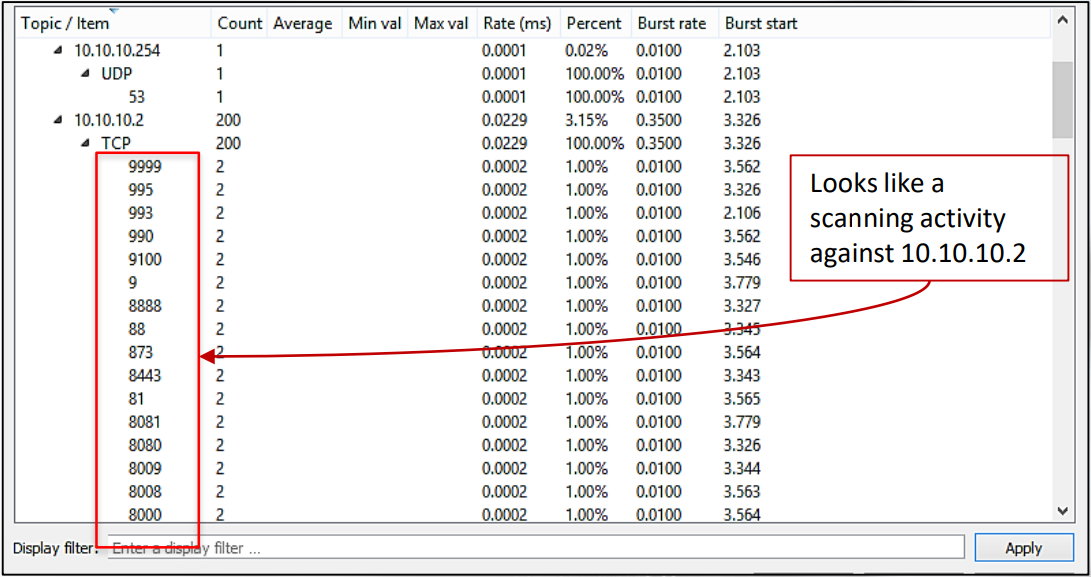
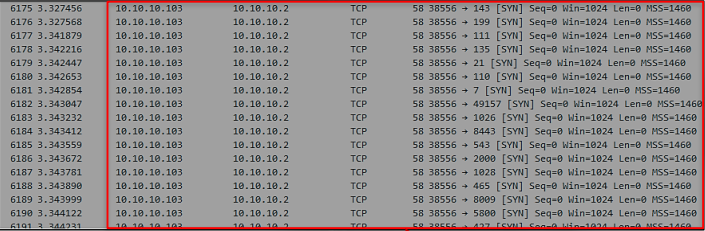
looking at the packet capture sequence to make sure that we are dealing with a scanning case:
- Host perimeter
- Detection occurs whenever we analyze data a host receives from the network or sends out to the network.
- Local firewalls or HIPS systems can assist such detection activities.
-
Example: When checking network and internet connections using netstat
netstat -naobcommand in windows, we can notice that a suspicious looking executable named winlogin.exe is listening on port 9999: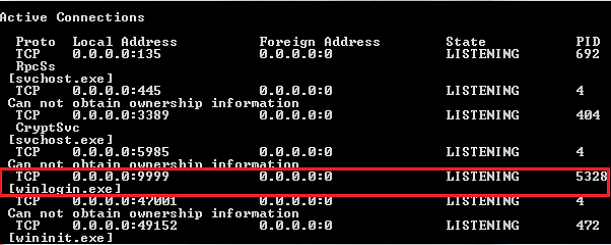
Note: Whenever performing detection activities at the host (or network) perimeter level, consider the following:
- Are the identified services actually running and part of your organization?
- If not, check for port abuse through resources, such as https://www.speedguide.net/ports.php to identify possible malware.
Example: We see a packet trying to reach port 21 of a host, or a host listening on port 21;
It could be FTP traffic if our organization includes such functionality or malicious traffic if it doesn’t.
- Host-level
- Detection occurs whenever We analyze data residing in the host.
- A/Vs and EDR solutions, as well as the users themselves, can assist in such detection activities.
- An example of host-level detection is a user being warned about a malicious executable by the host’s endpoint protection solution (such as Antivirus)
- Application-level
- Detection occurs whenever we analyze application logs.
- Web application logs, service logs, etc. can assist in such detection activities since they offer valuable insight, such as user operations, user input, etc., all accompanied by the respective time they were executed/submitted.
- Example: spotting abnormal behavior when statistically analyzing IIS logs.
Finally, before calling an event an actual incident, consider the following:
- Could this be a user oversight?
- Could this actually be the case or is this an improbability?
- Scrutinize all evidence.
- Base your decision on prior knowledge of the normal behavior.
In case you are handling an actual incident, ask yourself the following damage estimation questions:
- Identify the vulnerability’s exploitation impact. (Remote code execution should be handled much more quickly than information disclosure.)
- Are there any crown jewels that can be affected?
- What are the minimum requirements for effective exploitation? (A privileged position within the LAN; just an internet connection; Valid credentials; Default config; etc.? )
- Is this being actively exploited in the wild? (You can assess the adversary’s sophistication level this way.)
- Is there a proposed remediation strategy?
- Is there threat intel/evidence that suggests increased spreading capabilities?
Log-reviewing resource examples:
- Network perimeter
3. Containment, Eradication & Recovery
includes everything related to:
- Preventing an incident from getting worse (i.e., preventing the intruder from getting any deeper) ← Containment
- Eliminating intruder artifacts, understanding the root cause, attack vectors and TTPs in general, utilizing backups and improving ← Eradication
- Restoring and monitoring to make sure nothing evaded detection ← Recovery
Incident Classification:
Before Containment phase, We need to classify the incident based on the information we analyzed, We should know its Type, Impact & Extent
- Type:
- DOS, Info Leakage, External or Internal Exploitation, Malicious Email, Malware
- Impact:
- Incident affecting critical system(s)
- Incident affecting non-critical system(s)
- Incident affecting asset that requires no immediate investigation
- Note: Impact is tightly connected with the Response Time
- Extent:
- Extensive compromise, including sensitive customer information
- Manageable intrusion and spreading
- Immediately detected or easily contained intrusion
- Note: Extent is tightly connected with the escalation level. For example, should the CISO’s office or upper management be informed?
Incident Tracking:
Sometimes, the incident handling team will be required to handle multiple incidents; this is exactly why there should be an incident tracking mechanism. This can be done by using incident tracking & management tools such as RTIR (Request Trackers for Incident Response)
1. Containment
Containment is divided into the following 3 sub phases:
- Short-Term Containment (Render the intrusion ineffective)
- During this sub phase, we should try to render the intrusion ineffective, without altering the machine’s hard drive (we need to image it for forensic activities)
- To do so, we can disable network connectivity or even disconnect the machine from the power line, in extreme occasions.
- Place the machine in a separate/isolated VLAN
- Change DNS
- Isolate the machine through router or firewall configurations
- Always formally inform the respective business unit manager if you decide to do so, even ask permission.
- System Back-Up
- To preserve the evidence, you’re not supposed to work on the original machine when investigating and you’re also not supposed to analyze and work on the first image you take.
- The original image is usually verified and then saved alongside other parameters to protect it from tampering, while all the work is done on copies of the original image.
- When it comes to data acquisition, we have to consider the order of volatility. For example, the data within the machine’s RAM should be acquired first, since they are a lot more volatile than their on-disk counterparts.
- The storage mediums can be arranged from the most volatile to the least, as follows:
- Registers → CPU Cache → Ram → HDD → External & secondary storage devices
Volatile Data:
- The data on a live system that is lost after a computer is powered down. It resides in Registries, Cache Memory, and RAM.
- It can also exist on disk as a memory page due to paging, temp. files and log files.
Data Acquisition: The gathering and recovery of sensitive data or digital evidence during a digital forensic investigation.
Data Acquisition Types:
- Static Acquisition
- Is the acquiring process of data that are not volatile.
- By not volatile, we mean data that will not be affected by a system restart.
- Such acquisition is usually performed on hard disks and flash disks.
- Dynamic/Live Acquisition
- Is the acquiring process of data that are volatile.
- By volatile we mean data that will be heavily altered or even lost by any user action or system restart.
- Such acquisition is usually performed while a system is still powered on and without performing any prior actions.
- As running processes use RAM, it is very likely to find stored passwords, messages, domain names and IP address belonging to those processes.
Note: choosing which type to apply depends on data volatility & the incident.
- Dead Acquisition
- An analysis done on a powered off computer
- Is usually performed with the help of the system’s own hardware.
Acquisition approaches:
- From disk drive to image file (imaging) → we will focus on this approach
- Mirrors the under investigation hard disk’s content into an image file “Forensic image”.
- The advantage of this method is scalability and efficiency.
- From disk drive to disk drive (cloning)
Write Blockers:
- A tools ensures that data acquisition is performed without the risk of losing or altering data by blocking the hard disk from writing.
- Could either be hardware-based or software-based.
- Tools such as UltraDock & Tableau TD3 Forensic Imager

Evidence Integrity:
- Hash Functions are usually employed to validate the acquired evidence
- All calculated hash strings should be stored and communicated safely since they will be used to prove that the acquired data has not been altered.
- Many hash functions being used nowadays such as:
- SHA-1
- SHA-2
- SHA-3
- MD-5
- SHA-1 & MD-5 aren’t secure enough since they suffer from collisions
Remember that: Communicating with your ISP may be needed, especially in cases of DDoS attacks, worms, or phishing campaigns; this is due to the fact that ISPs not only have greater visibility when it comes to attacks in the wild, but they also keep useful logs.
After the imaging and live acquisition activities are completed, we have 2 ways;
- If the business unit manager/representative agreed on taking the system down, we can go straight to the Eradication phase, where we eliminate every attacker-related actions and residuals.
- If the affected system should stay as is, then it is time for long-term containment activities.
- Long-Term Containment (Make sure the intruder is locked out of the affected host and network)
- During this sub phase, we should try to render the intrusion ineffective, without altering the machine’s hard drive (we need to image it for forensic activities as we said before)
- Long-Term Containment activities such as:
- Affected & related system patching
- (H)IDS insertion
- Password(s) and trust(s) changes
- Additional ingress/egress rules (router & firewall)
- Drop packets associated with a source or destination identified in the incident
- Eliminate attacker access etc.
2. Eradication
Eradication should take place in order to make sure the attacker is locked out of the affected machine and network.
- We will have to identify the root cause and indicators of the incident. (Use information from the Detection & Analysis and Containment procedures)
- Isolate the intrusion and identify the attack vector.
- Important phases of Eradication:
- Eliminating attacker residuals:
- Removing malware such as backdoors, rootkits, malicious kernel-mode drivers, etc.
- In case of a Rootkit, zero the drive out, reformat and rebuild the system for trusted install media.
- Thoroughly analyze logs to identify credential reuse through Remote Desktop, SSH, VNC, etc
- Removing malware such as backdoors, rootkits, malicious kernel-mode drivers, etc.
- Improving defenses includes:
- Configuring additional router & firewall rules;
- Obscuring the affected system’s position;
- Null routing
- Establishing effective system hardening, patching, and vulnerability assessment procedures, etc. (Other systems in the network may suffer from the same vulnerability).
- Eliminating attacker residuals:
3. Recovery
Bringing the affected system(s) back to production.
Key Points:
- Process System Recovery:
- Once the affected system is restored, ask the business unit to perform QA activities to ensure the system’s running condition.
- Also, ask the business unit to ensure the system includes everything needed for their operations.
- Restore of Operations:
- A decision has to be made regarding when the restored system will enter production again.
- Consult/coordinate with the business unit for this matter.
- Monitoring:
- Once the restored system is back to production:
- Keep a close eye for oversights. Stealthy backdoors may still exist.
- Network, as well as host-based intrusion systems, should be utilized, looking for signs/patterns/signatures related to the original attack.
- Thoroughly analyze critical logs and events for signs of re-infection or re-compromise.
- What to look for during the weeks (or even months) to come:
- Changes to registry keys and values:
reg \\[MachineName] - Abnormal processes via wmic in windows:
wmic /node:[MachineName] /user:[Admin] /password:[password]orpsfor Linux - Abnormal user accounts:
wmic useraccount list briefornet user commandsorcat /etc/passwdfor Linux
- Changes to registry keys and values:
- Once the restored system is back to production:
4. Post-Incident Activity (Lesson Learned)
(taking a deep breath and reporting the identified weaknesses, oversights, blind spots, etc., regarding both our processes and technological measures)
- The respective incident handling team should start constructing an objective, accurate and thorough report regarding the lessons learned from handling the incident.
- The report should contain the identified weaknesses, oversights, and blind spots, working processes and successful detection methods.
- Holding a “lessons learned” meeting with all involved parties after a major incident will be helpful in improving security measures and the incident handling process itself.
- The meeting should be held within several days of the end of the incident.
- Questions to be answered in the meeting include:
- Exactly what happened, and at what times?
- How well did staff and management perform in dealing with the incident? Were the documented procedures followed? Were they adequate?
- What information was needed sooner?
- Were any steps or actions taken that might have inhibited the recovery?
- What would the staff and management do differently the next time a similar incident occurs?
- How could information sharing with other organizations have been improved?
- What corrective actions can prevent similar incidents in the future?
- What precursors or indicators should be watched for in the future to detect similar incidents?
- What additional tools or resources are needed to detect, analyze, and mitigate future incidents?
Appendix
1. Windows Cheat Sheet
User Accounts
Identify curious-looking accounts in the Administrators group [use lusrmgr.msc for GUI access]
- Related Command:
net user - Related Command:
net localgroup administrators
Processes
Identify abnormal processes [use taskmgr.exe for GUI access]
- Related Command:
tasklist - Related Command:
wmic process list full - Related Command:
wmic process get name,parentprocessid,processid - Related Command:
wmic process where processid=[pid] get commandline
###Services
Identify abnormal services [use services.msc for GUI access]
- Related Command:
net start - Related Command:
sc query | more - Related Command (associate running services with processes):
tasklist /svc
Scheduled Tasks
Identify curious-looking scheduled tasks [you can go to Start -> Programs -> Accessories -> System Tools -> Scheduled Tasks for GUI access to scheduled tasks]
- Related Command:
schtasks
Extra Startup Items
Identify users’ autostart folders
- Related Command:
dir /s /b "C:\Documents and Settings\[username]\Start Menu\" - Related Command:
dir /s /b "C:\Users\[username]\Start Menu\"
Auto-start Reg Key Entries
Check the below registry keys for malicious autorun configurations [use regedit for GUI access and inspect both HKLM and HKCU] ← You can also scrutinize every auto-start location through the Autoruns MS tool
HKLM\Software\Microsoft\Windows\CurrentVersion\RunHKLM\Software\Microsoft\Windows\CurrentVersion\RunonceHKLM\Software\Microsoft\Windows\CurrentVersion\RunonceEx- Related Command:
reg query [reg key]
Listening and active TCP and UDP ports
Identify abnormal listening and active TCP and UDP ports
- Related Command:
netstat –nao 10
File Shares
All available file shares of a machine should be justified
- Related Command:
net view \\127.0.0.1
Files
Identify major decreases in free space [you can use the file explorer’s search box and enter “size:>5M”
Firewall Settings
Examining current firewall settings to detect abnormalities from a baseline
- Related Command (XP/2003):
netsh firewall show config - Related Command (Vista-Win8 +):
netsh advfirewall show currentprofile
Systems connected to the machine
Identify NetBIOS over TCP/IP activity
- Related Command:
nbtstat –S
Open Sessions
Knowing who has an open session with a machine is of great importance
- Related Command:
net session
Sessions with other systems (NetBIOS/SMB)
Identify sessions the machine has opened with other systems
- Related Command:
net use
Log Entries
Identify curious-looking events [you can use eventvwr.msc for GUI access to logs]
- Related Command:
wevtutil qe security
2. Linux Cheat Sheet
Running Processes
Identify abnormal processes that could indicate malicious activity
- Related Command:
ps aux - Related Command (more details):
lsof –p [pid]
Services
Identify abnormal services
- Related Command:
service –-status-all← RedHat and Mandrake usechkconfig –listinstead
Scheduled Tasks
Identify curious-looking scheduled tasks
- Related Command:
crontab –l –u [account] - Related Command:
cat /etc/crontab - Related Command:
cat /etc/cron.*
Listening and active TCP and UDP ports
Identify abnormal listening and active TCP and UDP ports
- Related Command:
lsof –i← Compare this to a baseline - Related Command:
netstat –nap← Compare this to a baseline
ARP
Identify abnormal IP – MAC mappings
- Related Command:
arp –a← Compare this to a baseline
Files
Identify curious-looking files
- Related Command (abnormal SUID root files):
find / -uid 0 –perm -4000 –print - Related Command (overly large files):
find /home/ -type f -size +512k -exec ls -lh {} \;



